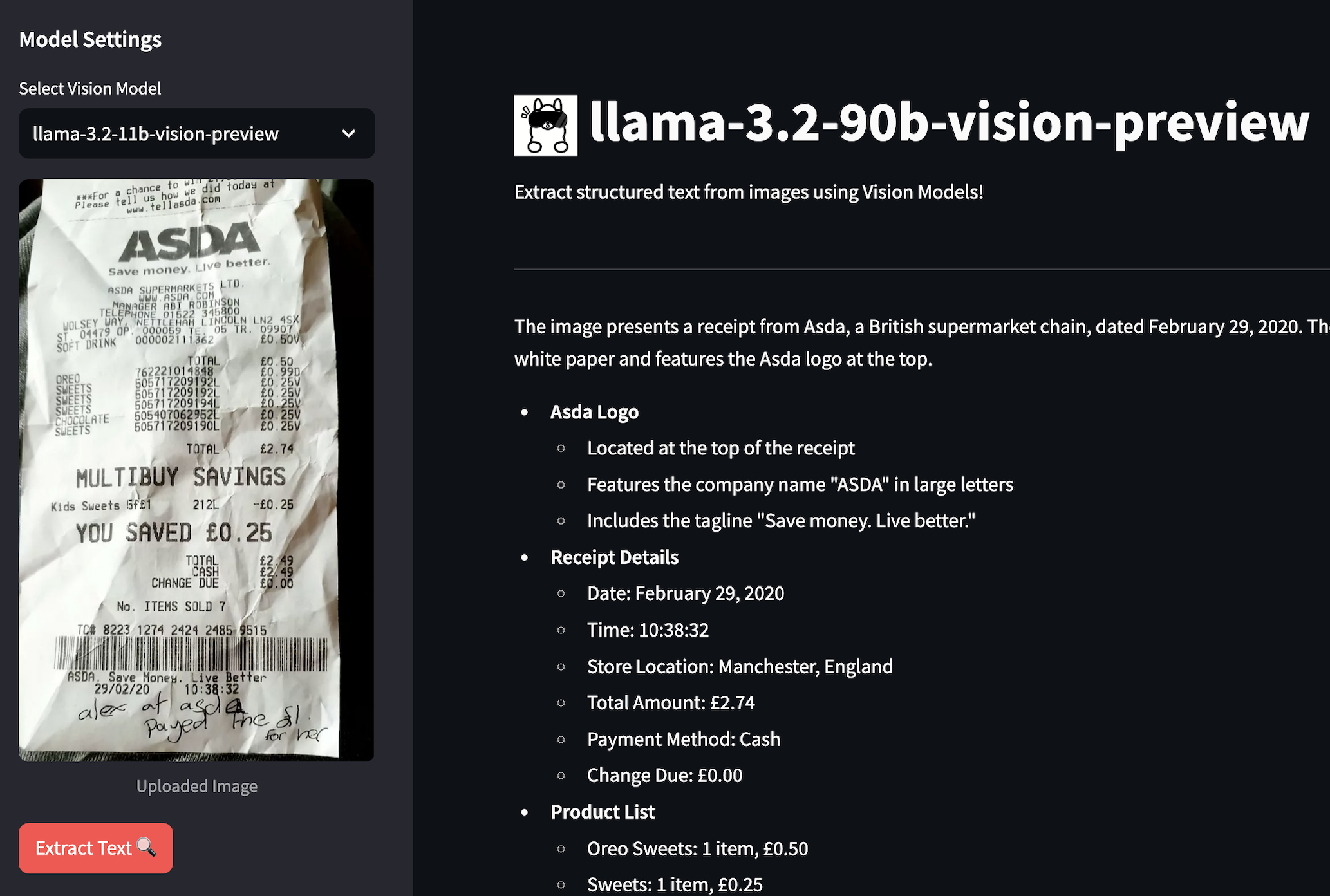

Vous avez déjà essayé de copier du texte depuis une note manuscrite ou une capture d’écran ? Ouais, c’est galère. C’est pourquoi j’ai décidé de créer quelque chose de cool en utilisant les nouveaux modèles vision Llama 3.2 de Meta. Cette petite app peut extraire du texte depuis des images - et oui, ça inclut aussi les écritures manuscrites illisibles ! Laissez-moi vous expliquer comment j’ai assemblé ça et pourquoi c’est vraiment génial.

Pourquoi Llama 3.2 ?
Les outils OCR traditionnels sont… disons qu’ils ne sont pas terribles avec autre chose que du texte imprimé parfait. Mais Llama 3.2 est différent - il comprend vraiment ce qu’il regarde.
J’ai testé les versions 90B et 11B paramètres. Le 90B est évidemment plus costaud et gère les trucs plus compliqués, mais honnêtement, le 11B est plutôt solide pour la plupart des cas aussi.
La stack technique
Puissance de calcul : Modèles vision Llama 3.2
Accélération : API Groq (inférence vraiment rapide)
Interface : Streamlit (parce que qui veut passer des semaines sur l’UI ?)
Traitement d’images : Le bon vieux Pillow
Liaison : Python & un peu de magie base64
Le Code




{kind=link}
Commentaires