

All of the above insights are drawn from the original Titan research paper: ArXiv Link.
🤔 Ever tried following a movie by watching random 10‑second clips? That’s exactly how most Transformers process long texts today: they chop documents into small chunks, analyze each in isolation, and never look back—so key connections vanish and responses go off‑rail.
👉 But there’s a better way. Titan isn’t just another language model—it’s built with a human‑like, three‑stage memory system that retains, recalls, and reasons over hundreds of pages. Let’s dive in.
Problem with transformers: A Concrete Example with the 200-Page Novel Challenge
![]()
Transformers process long documents by dividing them into smaller chunks and analyzing them separately. Since a Transformer can only handle 4,000 tokens at a time, a 100K-word novel must be split into 25 separate chunks (100K ÷ 4K = 25).
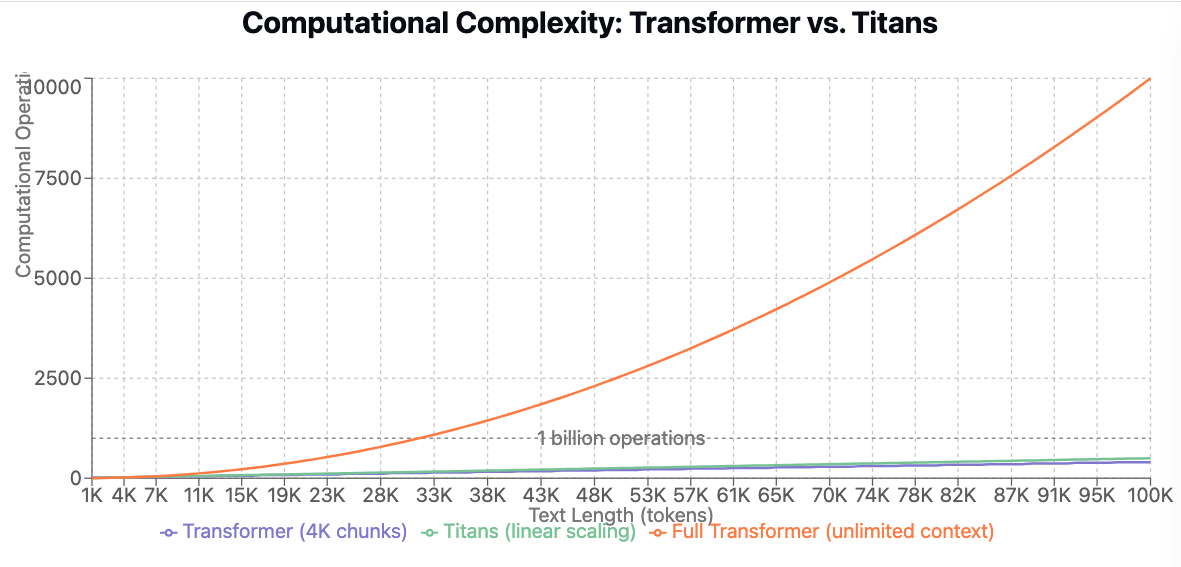
Within each chunk, Transformers analyze every word relationship, requiring 16 million operations per chunk (4K² = 16M). Across all 25 chunks, this results in 400 million operations, but no cross‑chunk links.
Before we explore how Titan’s memory system works, let’s take a moment to see how humans handle long narratives—with a memory architecture that inspired Titan’s model.
Human Memory: A Model for AI
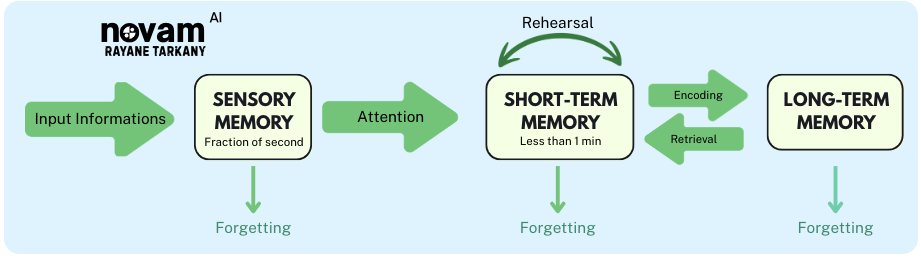
- Sensory Memory → The Core: Captures the “now”—holds the last few seconds of text for intense local attention.
- Short‑Term Memory → Neural LTM: An adaptive notepad: only surprising or contradictory events get written, via a learned “surprise metric.”
- Long‑Term Memory → Persistent Memory: A story‑sense encyclopedia that encodes genre patterns, foreshadowing, character arcs for future recall.
Titan Architecture Overview
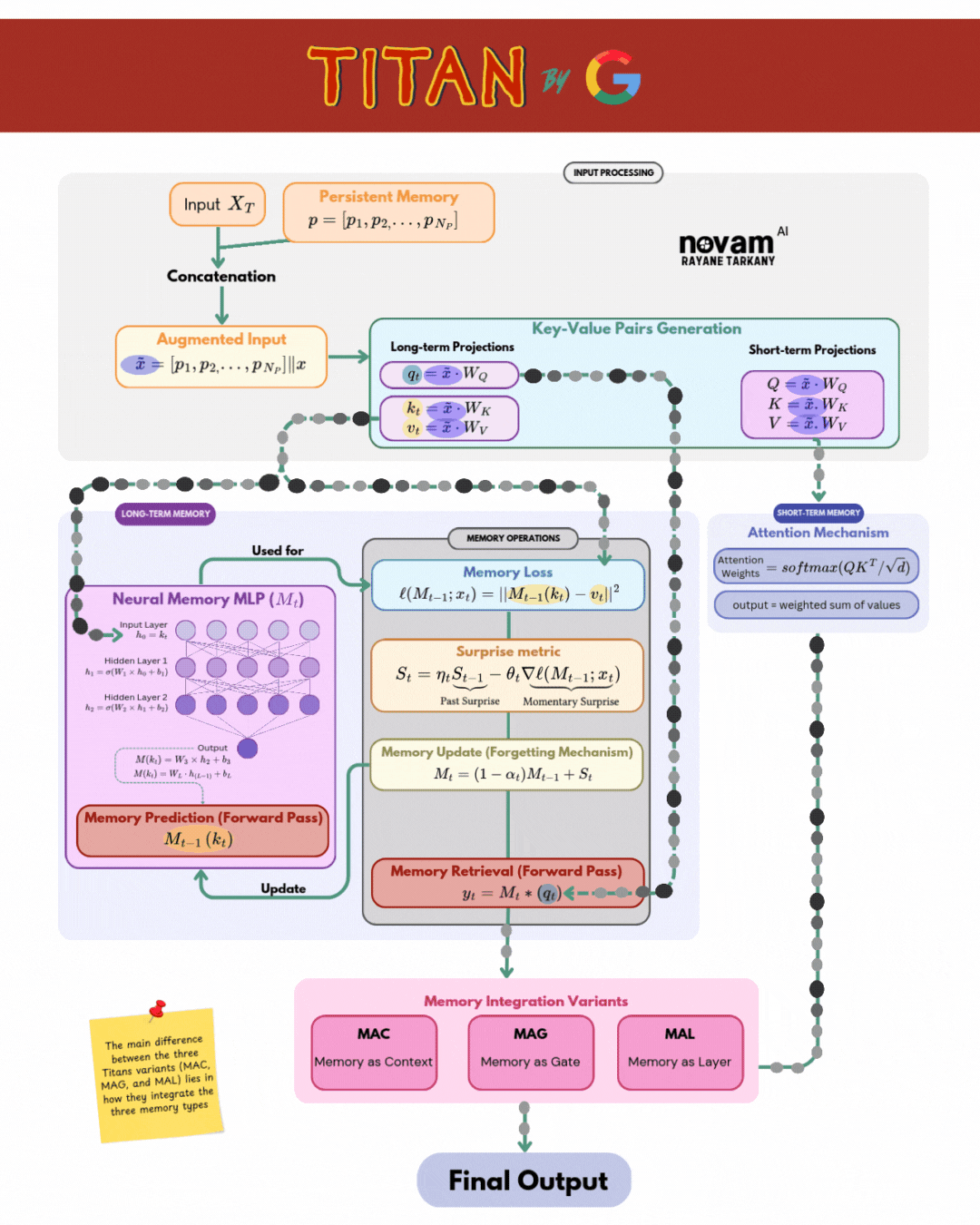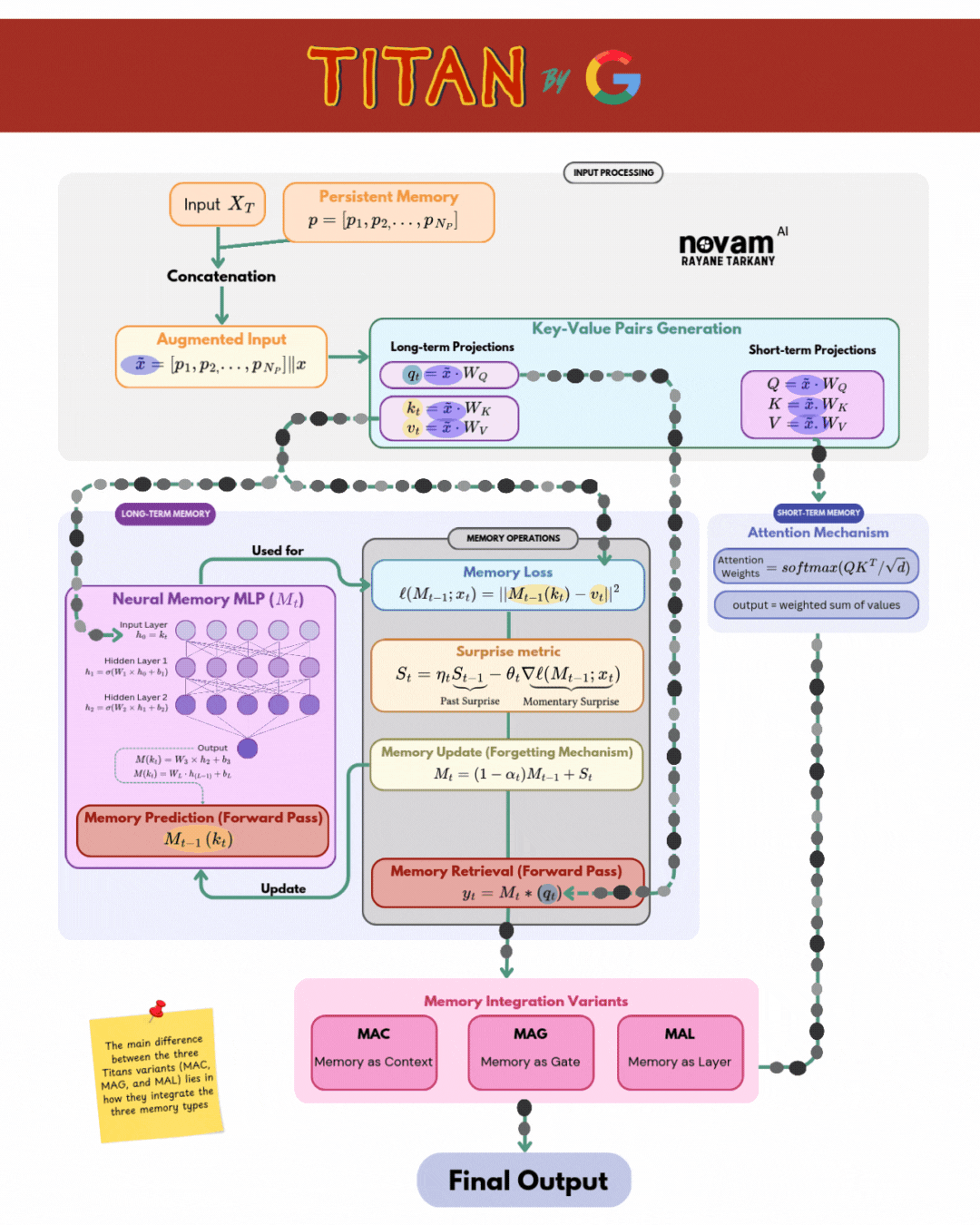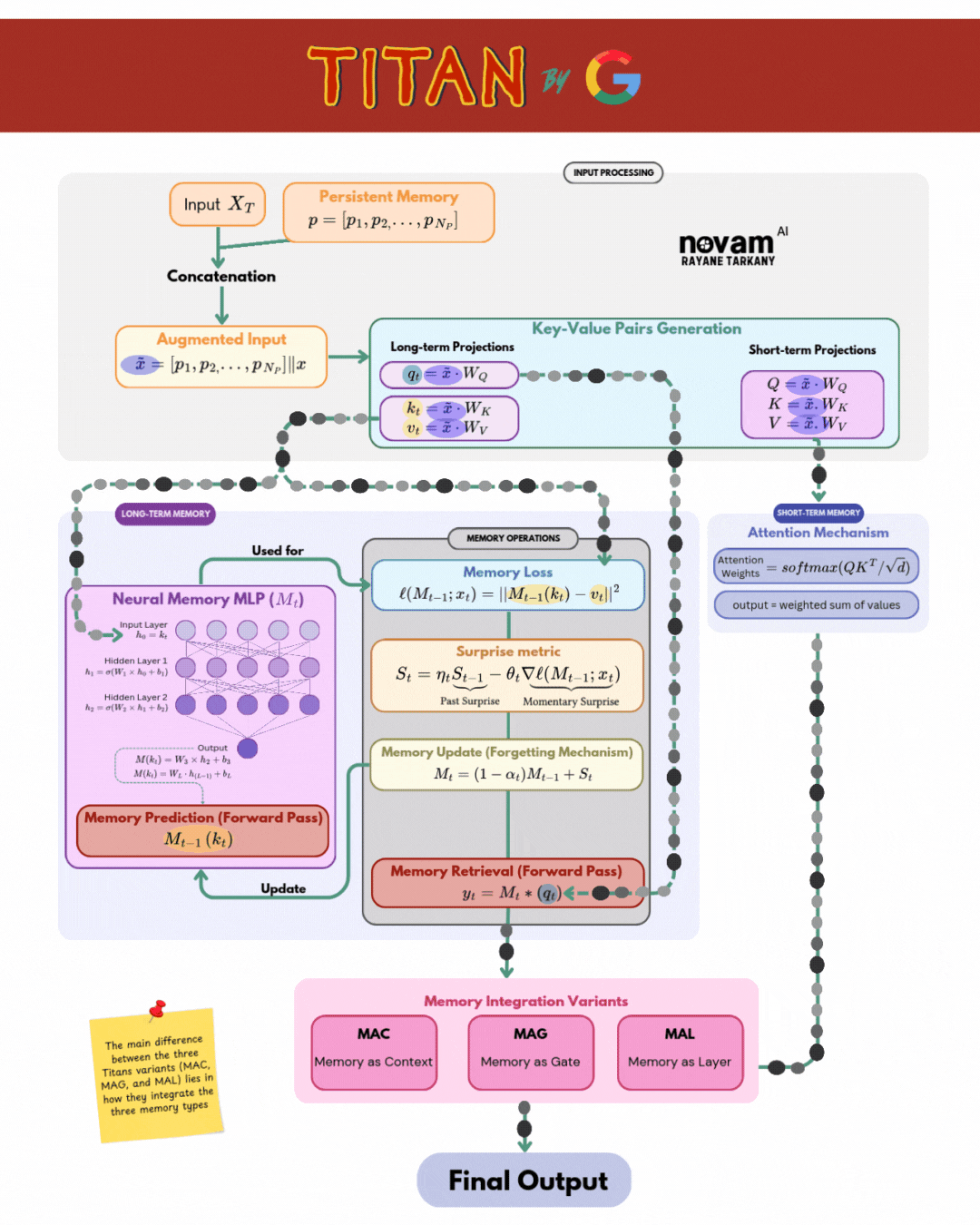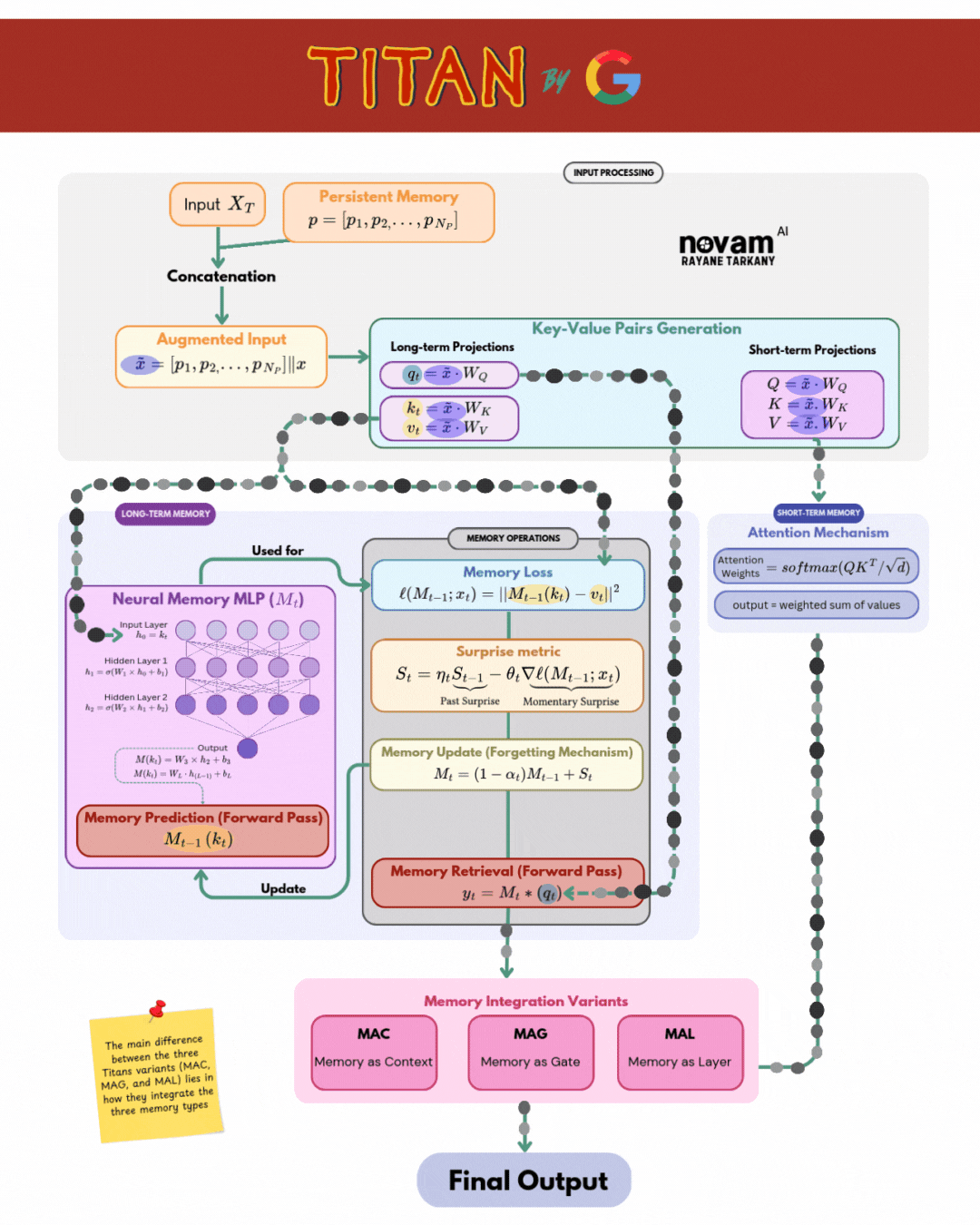
Titan composes three specialized “brains” into a single, unified model:
| Brain Component | Function | Key Mechanism |
|---|---|---|
| Core (Short‑Term Memory) | Captures and processes the immediate context (last L tokens) | Sliding‑window self‑attention over current tokens: \(\mathrm{Attention}(Q,K,V) = \mathrm{softmax}\Bigl(\frac{QK^\top}{\sqrt{d_k}}\Bigr)\,V\) |
| Neural Long‑Term Memory | Learns to store surprising or novel information at test time | Deep MLP memory module with surprise‑gated updates: \(S_t = \eta_t\,S_{t-1} - \theta_t\,\nabla_M \ell\bigl(M_{t-1}; x_t\bigr)\) \(M_t = (1 - \alpha_t)\,M_{t-1} + S_t\) |
| Persistent Memory | Provides a fixed, general knowledge store for long‑range context | Learnable key–value vectors ({(k_i, v_i)}) with global attention retrieval: \(r_t = \sum_i \frac{\exp\bigl(q_t^\top k_i / \sqrt{d_k}\bigr)}{\sum_j \exp\bigl(q_t^\top k_j / \sqrt{d_k}\bigr)}\,v_i\) |
Integration Variants
The three Titan variants each implement a distinct strategy for integrating long‑term and short‑term memories into the Core’s output:
- MAC (Memory as Context): Concatenates retrieved (r_t) to the Core inputs—treating memory just like extra tokens.
- MAG (Memory as Gate): Uses (r_t) to modulate the attention weights via learned gating functions.
- MAL (Memory as Layer): Inserts a dedicated memory layer, combining (h_t) and (r_t) through a learned transformation.
What’s Worth Remembering
The real magic happens in how Titans determine what information should be stored in long-term memory. They use what the researchers call a “surprise metric” that considers:
- Momentary Surprise: “Whoa, I didn’t expect that plot twist!”
- Past Surprise: “This connects to that other surprising moment from earlier!”
This approach mimics how humans remember—we don’t remember every single detail of a book, but we definitely remember the shocking twist ending!
👉🏻 In the next article, we will explore the three variants of the Tian model: MAC, MAL, and MAG.


{kind=link}
Commentaires